We value your privacy
This website uses cookies to ensure you get the best experience on our website.
 Skip to main content
Skip to main content
This website uses cookies to ensure you get the best experience on our website.




Research shows that consumers can make purchasing decisions in as little as 313 milliseconds, making it crucial to influence the process within the first 3-5 seconds. Read more: http://journal.sjdm.org/11/10420a/jdm10420a.pdf
There are various eye-tracking options available, from webcam technology to open-source software. However, due to technical constraints, these cheaper alternatives often produce data that results in lower levels of accuracy and precision. That’s why we only use the latest gold-standard eye-tracking equipment in our lab-based studies. The cameras detect infrared spectrum light and also benefit from outstanding technical specifications specialized to optimize particular eye-tracking tasks (mitigating spatial noise, head movements, changing illumination or calibration decay). These features work together to create a highly accurate system that produces highly reliable data.
Our neuroscientists are continuously testing the accuracy of our eye-tracking techniques. Here’s a recent paper outlining the findings: https://www.researchgate.net/publication/330850931_A_new_comprehensive_Eye-Tracking_Test_Battery_concurrently_evaluating_the_Pupil_Labs_Glasses_and_the_EyeLink_1000
Dozens of new models on fixation prediction are published every year and compared on open benchmarks such as MIT300 and LSUN. However, progress in the field can be difficult to judge because models are compared using a variety of inconsistent metrics. Here at EyeQuant, we rely on our network of scientific advisors from the University of Caltech and dedicated neuroscientist from the University of Osnabrueck to continuously evaluate our predictive algorithms.
EyeQuant’s research team is a leader in the field of evaluation methods for predictive models. The metrics used to measure accuracy depend on the type of prediction being made. For example, attention predictions are evaluated using 4 statistical metrics. This peer-reviewed paper by people on our team provides a detailed look at them: Measures and Limits of Models of Fixation Selection
EyeQuant’s attention prediction models are around 90% as accurate as the real eye-tracking studies’ data that the models are based on. How do we determine this and what does this comparison even mean?
The primary metric by which we measure accuracy is the so-called area under the receiver-operator characteristic, AUC in short. This metric is very commonly used in science and in particular also in measuring performance of models of human attention. Simply put, it quantifies how much a model is capable of distinguishing between bits of a stimulus, like pixels on a computer screen, that are likely to be fixated from those that are unlikely to be fixated.
While computational models, like artificial neural networks, can be used to predict the probability of eye fixations on areas of a web design after they have been trained with real eye-fixation data, one can also think of a subset of eye-fixation data itself as a model of a disjunct subset of eye-fixation data from the same experiment. This is done to understand an intrinsic property of the experimentally collected data: the upper limit that can be achieved by any model when based on that data.
In our method, to determine this upper limit, we take the eye-fixation data of one group of subjects to predict the eye fixations of a different group of subjects for all stimuli shown in the experiment. We select the predicting group such that their performance of predicting fixations of the other group is optimal – again, within the data’s own bounds: the accuracy score is practically never the perfect 1.0 AUC, because there is a natural variability of the fixation behavior between subjects. More typically such models derived directly from an optimal subset of the empirical data have an accuracy of around 0.9 AUC in our experiments.
While achieving an accuracy of just about 0.82 AUC our computational models have the advantage to be able to generalize beyond the ground truth. They have learned principles of human eye fixation and can apply those to new stimuli, like web designs, they have never been exposed to before. At the same time, when we validate them by testing them on parts of the ground truth after training them with the rest of the ground truth, they also are bound by the above-mentioned limit of the data. This is still the influence of the natural variability in fixation behavior in a sample of the population.
That means that if our models score an accuracy of about 0.82 AUC in their validation, they are – as 0.82 is 90% of 0.9 – in fact 90% as good as they theoretically can be given the nature of the ground truth. Or to put it as we did in the beginning: they are around 90% as accurate as the real eye-tracking studies’ data that they are based on.
Below, you’ll find an example of an accuracy graph for Attention:
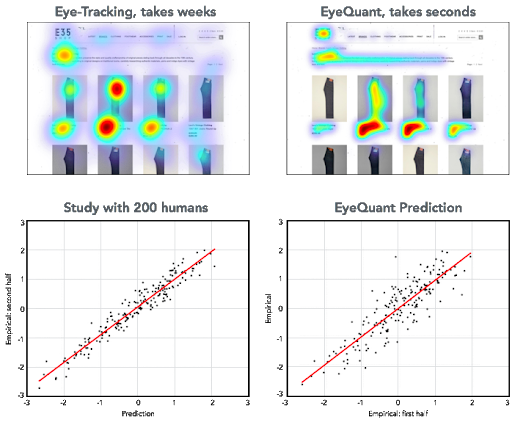
For details on specific approaches for measuring the accuracy of our models of human attention, please see the following paper: Measures and Limits of Models of Fixation Selection (PLOS ONE, 2011). Niklas Wilming, Torsten Betz, Tim C. Kietzmann, Peter König