We value your privacy
This website uses cookies to ensure you get the best experience on our website.
 Skip to main content
Skip to main content
This website uses cookies to ensure you get the best experience on our website.




As a partner in the NextGenVis programme for “Training the Next Generation of European Visual Neuroscientists” 2016-2019, EyeQuant is proud to present a guest post by fellow Alex Hernandez-Garcia, who researches innovative training methods for deep neural networks:
As a machine learning engineer and scientist, a few years ago I had to avoid the terms “machine learning”, “deep learning” or “neural networks” when someone asked about my job. Thankfully, more and more people are now aware of the revolution that these fields initiated.
Virtually everyone in the field would point out the availability of large labelled data sets as one of the decisive factors for the success of deep learning in many fields. However, since the advent of the first successful models, most efforts have been devoted to finding better, innovative architectures, new ways of training very deep models and coming out with effective regularization techniques to prevent the algorithms from over-fitting the training data. Meanwhile, little attention has been given to the data, especially within the research circles.
Most deep learning practitioners are well aware of how hard and expensive it is to collect large labelled data sets, in some cases, and the great difference it makes when good data are available. In the image domain, such as visual object recognition, an obvious way of having some more data “for free” has always been to apply “data augmentation”. Data augmentation consists of synthetically expanding a data set by applying transformations on the existing examples that preserve the label, for example, translations or mirroring of the images.

Data augmentation is almost ubiquitous in the training of neural networks for image object recognition. However, until recently little was known about the actual effectiveness and potential of data augmentation or its interaction with common regularization techniques. For instance, most people use data augmentation, weight decay and dropout, all together, since all three are well known to improve generalization. Nonetheless, the paper “Do deep nets really need weight decay and dropout?”first questioned the need for explicit regularization (such as weight decay and dropout) in deep learning and showed that data augmentation alone could outperform the models with all techniques combined.
Surprisingly, models that had achieved state-of-the-art performance in object recognition benchmarks, such as the all convolutional net, obtain even better performance if weight decay and dropout are removed. The reason is simply that weight decay and dropout were unquestioned and data augmentation undervalued.
In this regard, perhaps even more interesting was to discover the high adaptability of data augmentation to changes in the network architecture and the amount of training data, especially compared to the strong dependence of weight decay and dropout on their sensitive hyperparameters. In “Data augmentation instead of explicit regularization”we extended the set of ablation experiments by training models with and without explicit regularization; with and without data augmentation; deeper and shallower networks; with different amounts of training data. Very consistently, modifying the architectures dramatically hindered the models trained with weight decay and dropout. On the contrary, training with just data augmentation smoothly adapts to the new scenarios.
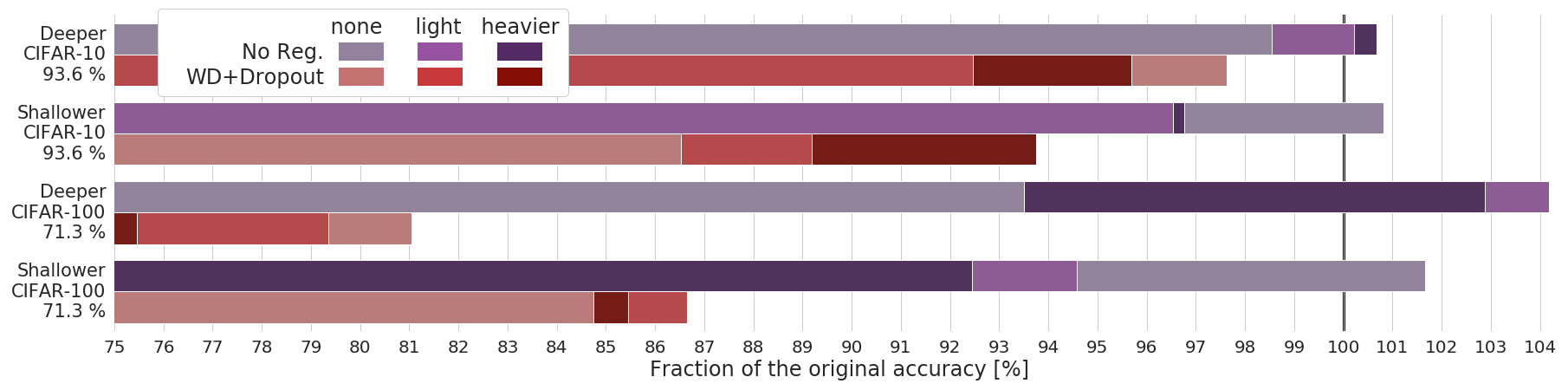
There is an intuitive reason for this behaviour: when you add weight decay and dropout to your models, you have to specify how much, where exactly in the network, where not. These are the hyperparameters of the regularization techniques, which are extremely sensitive to changes in the architecture. There are two intuitive solutions: One, spend a lot of valuable training time adjusting the hyperparameters to find the sweet spot. Second, do not use weight decay and dropout at all!
Data augmentation, however, does not depend on such sensitive hyperparameters. One defines a set of allowedtransformations that preserve certain degree of similarity with the original image and simply apply some of these transformations to the input images while training. The traditional criticism of data augmentation is that it depends on expertknowledge to define allowed the transformations. First, that is not necessarily a bad thing and also expert knowledge is implicitly present in the labeling of the data set, for instance. Second, the regained attention on data augmentation has encouraged researchers to develop new techniques of automatic data augmentation, made very popular by Google’s AutoAugment.
Finally, another interesting aspect of data augmentation is its connection with visual perception in the brain. Our visual brain is constantly fed with continuously changing visual stimuli. This probably helps create very robust neural connections to changes in the pose, light conditions, occlusion, etc. On the contrary, we expect our artificial neural networks to become similarly robust by training them with just still images. Data augmentation is not the perfect solution, but it is a step towards introducing more variability in the input data. As a pilot test of this hypothesis, we compared the representations learnt by a neural network with fMRImeasurements when participants saw the same images. We found that “deep neural networks trained with heavier data augmentation learn features closer to representations in higher visual cortex”.
Taken together, if you are into deep learning and include explicit regularization in your models, such as weight and dropout, you may want to try switching them off and explore ways of applying creative data transformations. You will train faster, save valuable time from fine-tuning hyperparameters and probably improve the performance!



Why do users miss what seems obvious? In our latest webinar, Professor Peter König, one of the world’s leading...
Read more
In this session, we explored how teams can move beyond instinct and start making creative decisions based on how...
Read more
What does attention prediction actually look like in day-to-day design work? In this month’s webinar, we’re joined by leading...
Read more